对 RNN 系成员的一些总结。
# RNN
这是一个三维低等生物眼里的 RNN:

这个细胞(绿色的框)相当于 Keras 中一层 RNN 的隐藏层,一个隐藏层可能有多个神经元。它在 时刻的状态(隐状态)叫做 ,是一个向量,向量维数与这个隐藏层的神经元数量相等,每个神经元的值都是一个标量。
这是一个四维高等生物眼里的 RNN(按时间步展开):
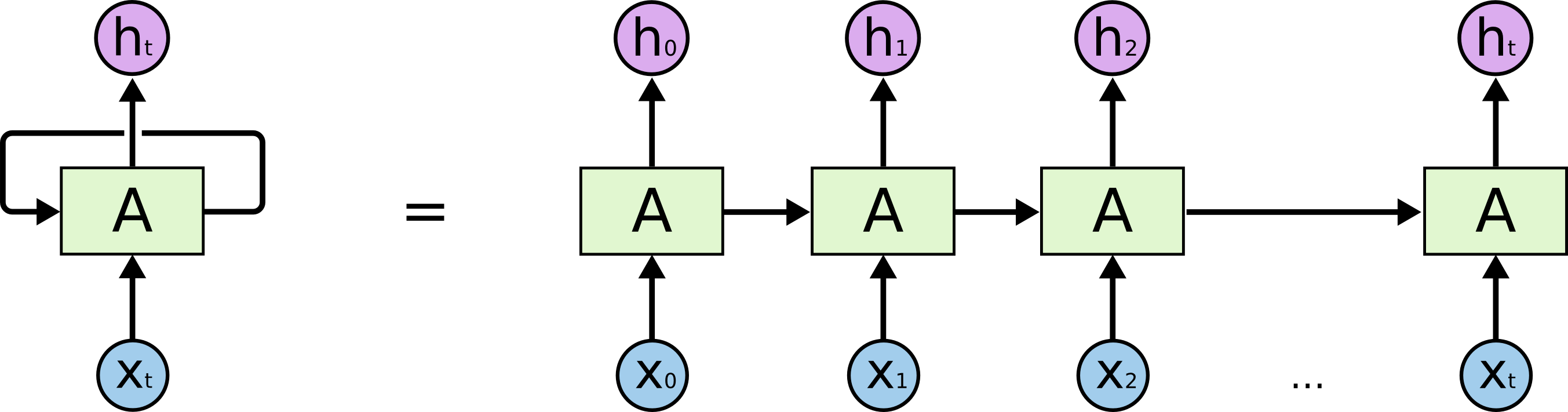
如果画得详细一点:
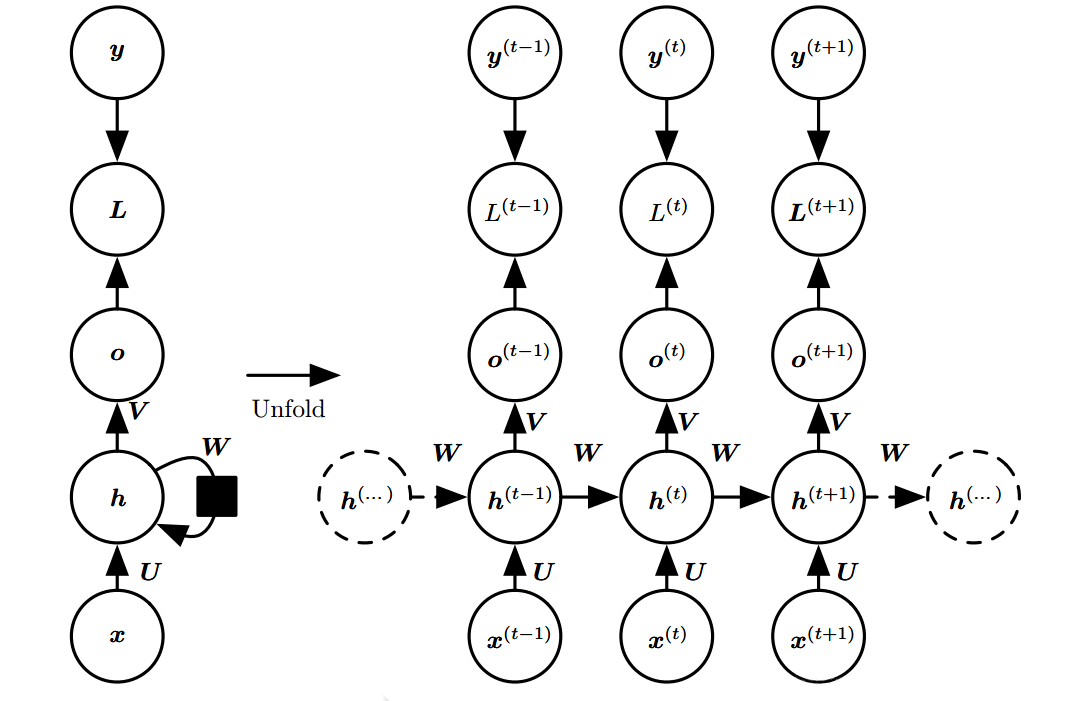
其中:
- : 时刻的输入向量;
- : 时刻的隐状态;
- : 时刻的输出(只由 决定);
- : 时刻的损失函数,最终的损失函数是 ;
- : 时刻的真实结果(ground truth);
- :权重矩阵,要学习的参数,在所有时间步中都是共享的;
上一个时间步的隐状态 会在 时刻乘一个权重矩阵 然后重新输入细胞,也就是 同时依赖于 和 。
# 前向传播
符号说明:
- :激活函数;
- :偏置向量(bias);
- :模型在 时刻的最终输出;
公式:
损失函数 的作用就是量化模型在当前位置的损失,即 和 的差距。
# 反向传播
整体损失函数:
有参数 ,先对它们随机初始化,然后在每个迭代周期对各参数求梯度,并按梯度的方向更新这些参数以使 最小化:
其中 是学习率, 是损失函数在 位置的偏导数,即梯度。
没有长期依赖,所以偏导好求一些:
而正向传播中, 对 还有贡献,所以反向传播计算 在 时刻的梯度时,还需要考虑 时刻的梯度(全导数)。
先求 时刻隐状态的梯度:
当 时,需要从 时刻递推到 时刻隐状态的梯度:
当 时,因为已经是最后一个时刻了,所以:
然后 的梯度为:
# 梯度消失和爆炸
如果直接把 在 时刻的偏导式展开:
同理, 在 时刻的偏导式展开为:
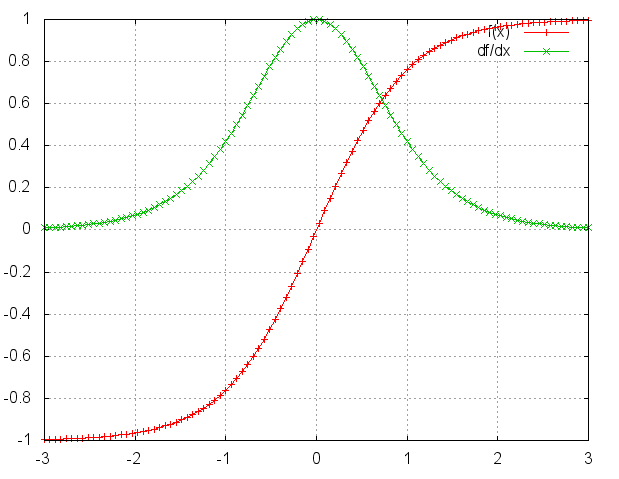
通过激活函数得到,假设激活函数为 tanh:
tanh 函数的函数图像和导数图像为:
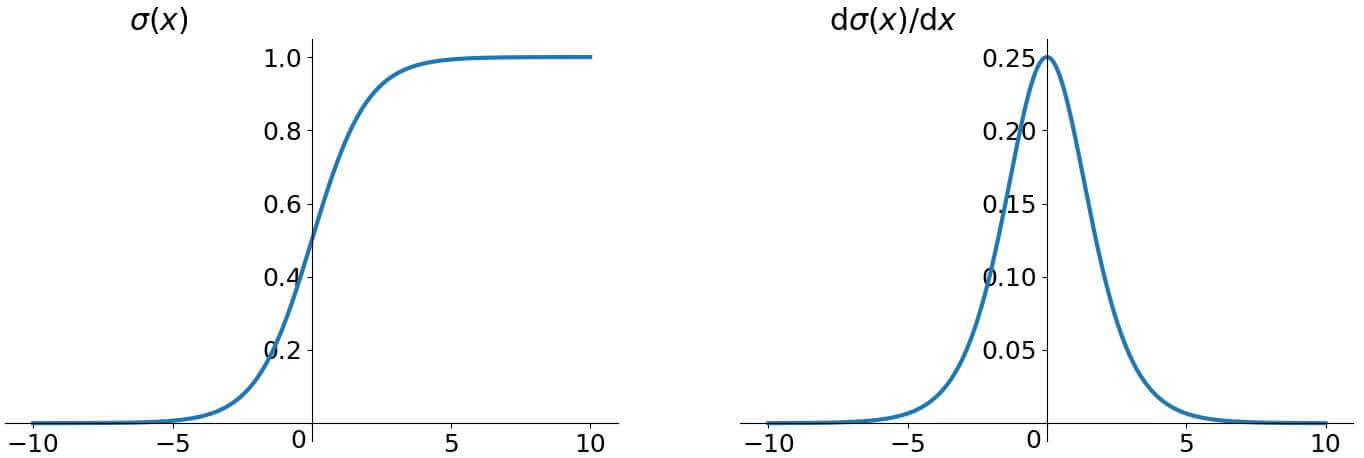
假设激活函数为 sigmoid:
sigmoid 函数的函数图像和导数图像为:
梯度消失:
可以看到,这俩函数的导数范围都不会超过 1,如果 的初始化值也在 之间,那么就是一堆 之间的小数在连乘,乘到最后就会导致梯度越来越接近于 0,造成梯度消失。
在 DNN 中,某一层的梯度消失就意味着那一层的参数再也不更新,那一层的隐层就变成了单纯的映射层。
而 RNN 中,梯度是累加的,就算较远时刻的梯度趋近于 0,累加后的整体梯度依然不会为 0,整体梯度是不会消失的。但这会造成 RNN 被近距离梯度主导,只能利用的有限的历史数据,难以学到远距离的依赖关系。
但相比 sigmoid,tanh 函数的梯度还是更大一点,所以收敛速度要快一些,且引起梯度消失更慢。
而解决梯度消失可以靠换激活函数(ReLU、LeakyReLU、ELU 等)或改传播结构(LSTM、Batch Normalization、ResNet 残差结构)。
如,ReLU 激活函数的函数图像和导数图像为:
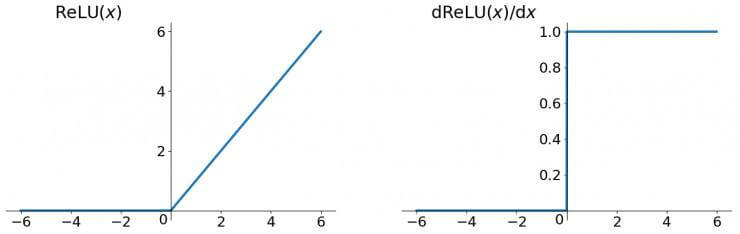
因为 轴右侧导数恒为 1,所以避免了梯度消失的问题。但恒为 1 的导数容易导致梯度爆炸,所以需要一些调参技巧,比如给梯度设定合适的阈值,如果大于这个阈值,就按这个阈值进行更新。
梯度爆炸:
而如果 的初始化值非常大,那连乘起来就会梯度爆炸。梯度爆炸意味着可能因为过大的优化幅度而跨过最优解,导致前面的学习过程白费。
# LSTM
Long Short-Term Memory. Sepp Hochreiter and Jürgen Schmidhuber. Neural Computation 1997. [Paper]
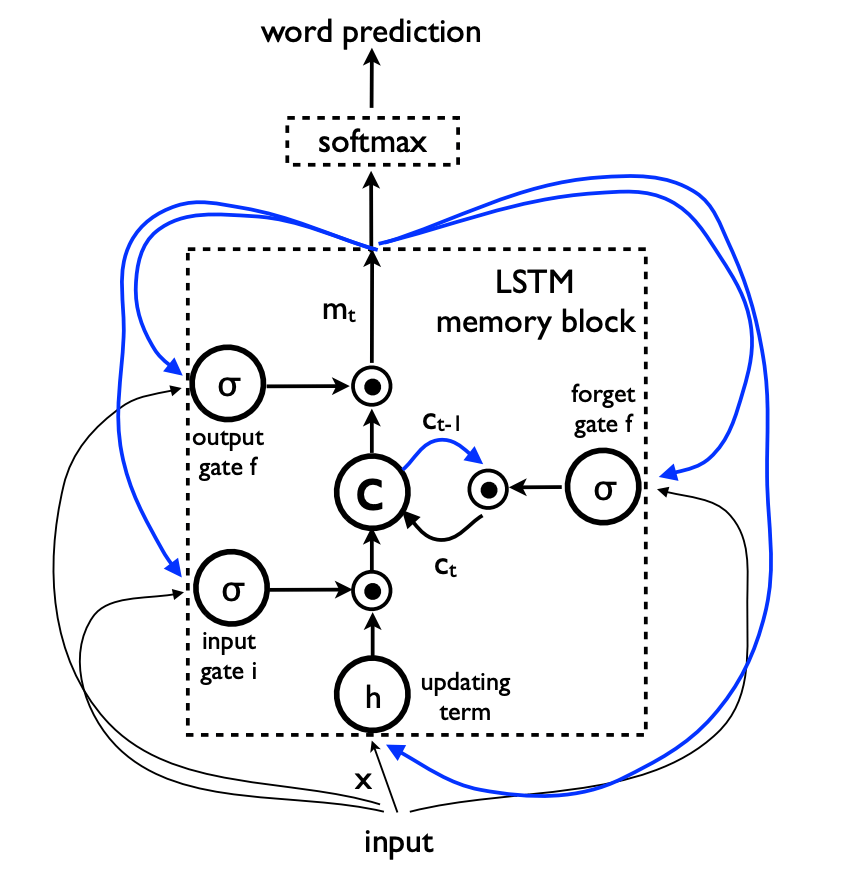
一般来说应该放一张这样的图:
同样,这个细胞相当于 Keras 中一层 LSTM 的隐藏层,隐藏层里有四个前馈网络层。图里的 4 个黄色框每个都是一个前馈网络层,它们的激活函数分别为 sigmoid(1,2,4)和 tanh(3)。
Hidden Units(Keras 的 units)就是每个前馈网络层的神经元个数。
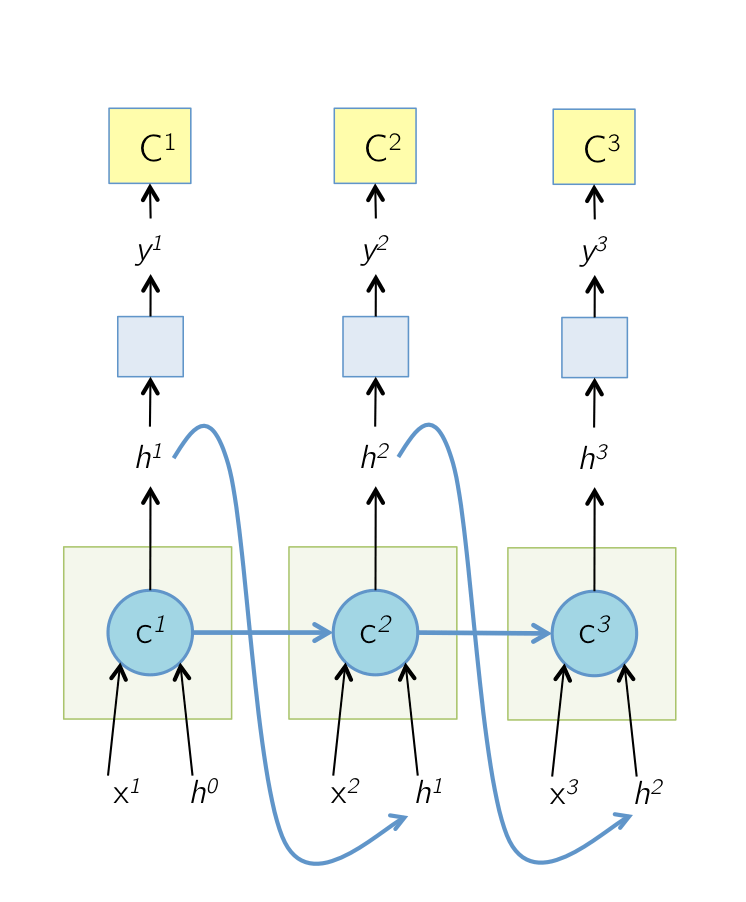
另一种画法(论文 Show and Tell),虽然它似乎把 output gate 写成了 output gate (...):
LSTM 的核心是一个由 3 个门控制的记忆细胞 。 时的隐状态 会被用于当前细胞状态的损失计算,和下一细胞状态( 时)的隐状态 的计算,所以 会在 时经过这 3 个门重新进入细胞。
# 前向传播
传播流程:
后面公式中的符号说明:
- :sigmoid 激活函数,会把矩阵转换为一个介于 0 和 1 之间的值作为门控信号,0 表示完全遗忘,1 表示完全接受;
- :tanh 激活函数,会把矩阵转换为一个介于 -1 和 1 之间的值;
- :哈达玛积(Hadamard Product),即俩矩阵对应元素相乘,所以要求俩矩阵同形
# 遗忘门
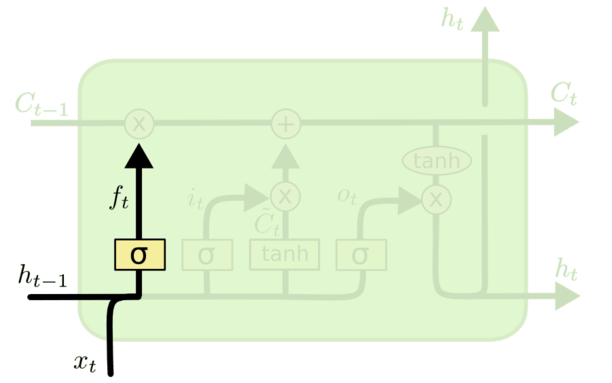
Forget Gate,对上一个细胞状态传进来的信息进行选择性遗忘。会根据 和 来为上一个细胞状态 计算一个门控信号,计算公式为:
然后把 跟 相乘,就是最终从上一个状态输入的内容:
# 输入门
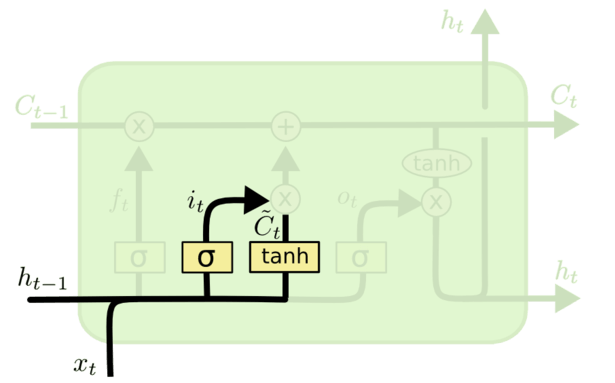
Input Gate,对现阶段输入 进行选择性记忆,更新细胞状态。由两个部分构成:
sigmoid 激活函数,计算门控信号,控制要记忆哪些内容:
tanh 激活函数,计算现阶段新学到的东西:
这俩相乘后的结果就是最终被记下来的现阶段新学到的东西,再加上从上一个细胞状态输入的内容就是更新后的细胞状态。所以细胞状态的更新公式为:
# 输出门
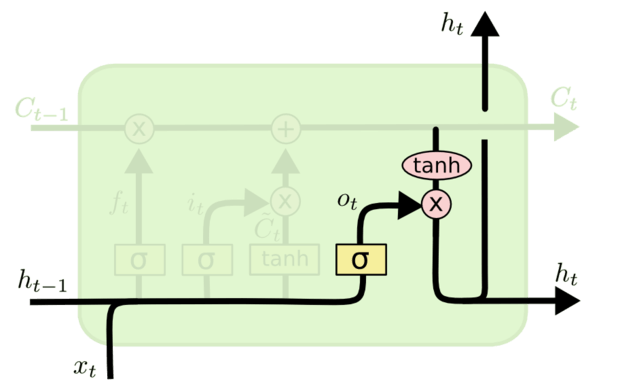
Output Gate,现在细胞状态已经更新了,所以要决定那些状态最终会被输出(隐状态 )。依然用 sigmoid 激活函数来计算一个门控信号,控制要输出哪些内容:
然后把它跟用 tanh 激活函数放缩过的当前细胞状态 相乘,就是这个阶段最终输出的隐状态:
# 最终输出
最终的输出 会由 变换得到,常见的做法大概是把 扔进 softmax:
# 反向传播
传播流程:
公式以后再说,我已经跑偏太多了...
# GRU
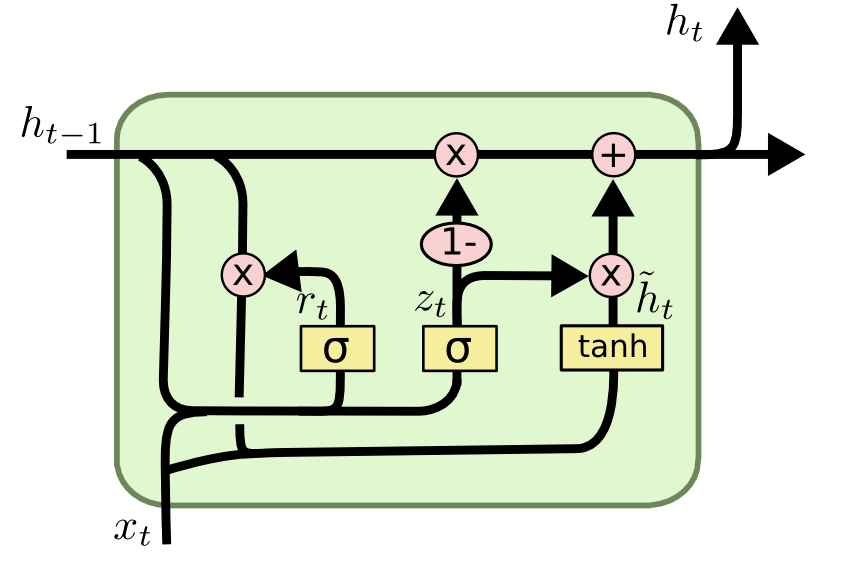
GRU 是 LSTM 的变体。它只有两个门,重置门 和更新门 (用一个门达到了遗忘和输入的目的)。它还合并了隐状态和细胞状态。它的模型结构比 LSTM 简单,但同时能达到跟 LSTM 相当的效果。
# 重置门
Reset Gate,先计算重置门控信号 ,用于控制要保留上一个时刻的多少信息:
然后计算当前时刻的候选隐状态(candidate hidden state):
相当于 主要包含了当前输入 的信息,然后有选择性的加入上一时刻的信息()。
# 更新门
Update Gate,先计算更新门控信号 ,用于控制要从 中遗忘多少信息和要从 中记忆多少信息:
然后直接算出当前时刻隐状态 :
可以理解为 对标 LSTM 中的遗忘门控, 对标 LSTM 中的输入门控。